
Why Your Current Autoscaler is Holding You Back: The Karpenter Revolution
Little Background of Karpenter
Karpenter came out in 2021 from AWS, and it’s a big deal for Kubernetes because it fixes some old problems. Kubernetes is super popular for running apps in containers, but as more people use it from small companies to big one, they have issues with managing resources. The old tools worked okay before, but they couldn’t keep up with today that must be fast and tricky workloads. Let’s break down the big problems that led to Karpenter and why it’s shaking things up.
What was Wrong with the Old Tools?
The main tool people used before, called the Cluster Autoscaler, worked okay for basic stuff but started falling apart as things got more complicated. Here’s some problem that traditional autoscalers had.
- Stuck with fixed options The old autoscaler made you pick groups of nodes ahead of time, with set sizes and types. Changing these groups by hand was a hassle and easy to mess up.
- Slow to react When your app suddenly got busy, the old tool took some minutes to add more nodes. It had to pick a group, set up the machines, and get them ready, which could take too long.
- Wasting resources The old autoscaler wasn’t great at using nodes fully. You would end up with nodes half empty, what does that mean? It’s like renting a big house with many rooms but only using one room.
On the diagram below may help you to understand why Karpenter is more than better to replaced the old tools.
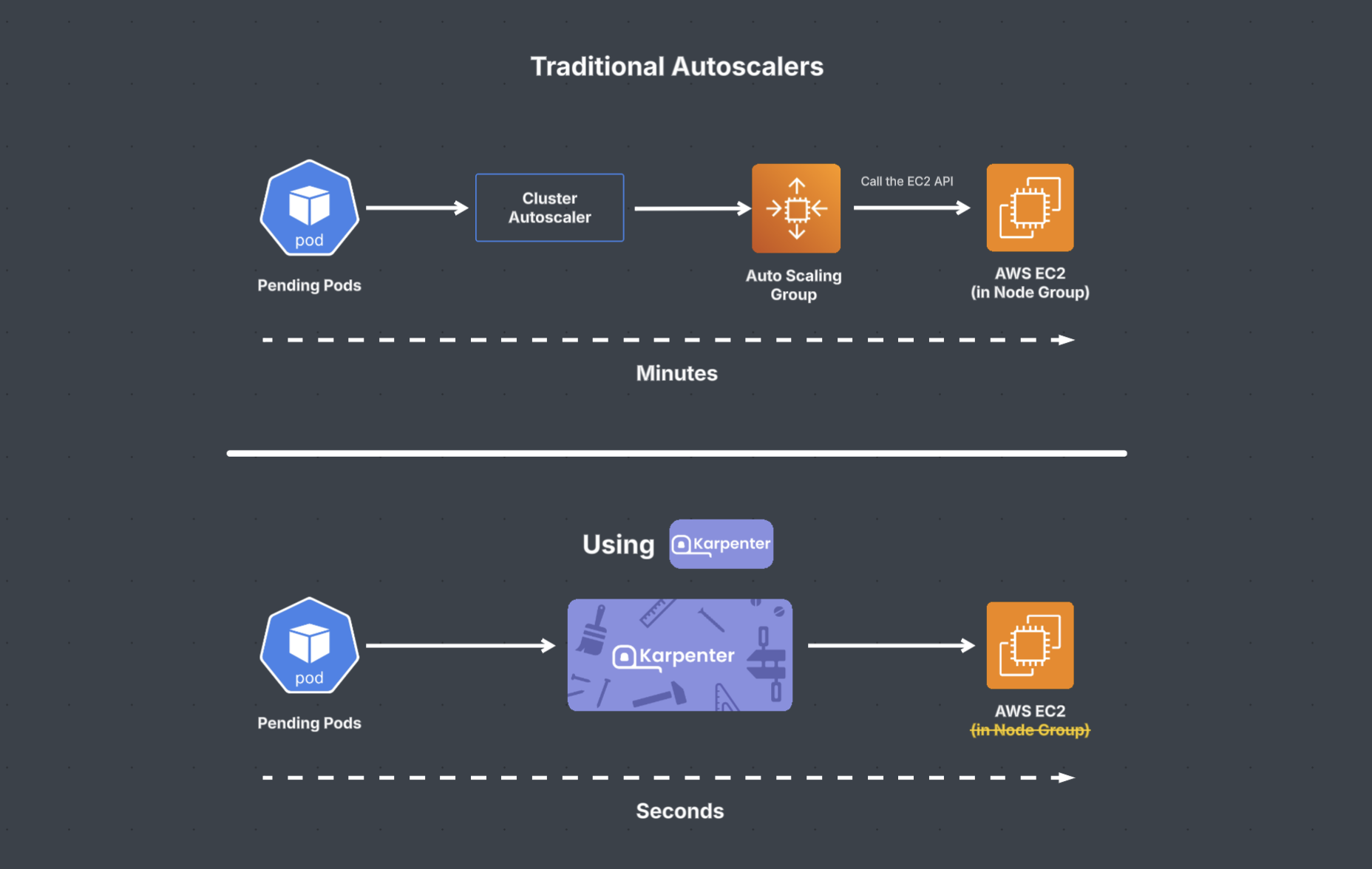
Karpenter does more than just traditional autoscalers. While its primary role is to automatically adjust the number of nodes in a Kubernetes cluster based on resource demand much like a standard autoscaler. Karpenter seamlessly integrates with spot instances, which are typically cheaper than on-demand instances. It not only uses these cost-effective resources but also manages interruptions effectively, ensuring your workloads remain stable while reducing cloud cost. Karpenter also optimizes resource usage by consolidating workloads onto fewer nodes when demand decreases.
In short, while Karpenter is fundamentally an autoscaler, its additional capabilities that flexible on provisioning, spot instance support, workload consolidation, and smarter scaling go beyond basic autoscaling. These features make it an advanced tool for managing Kubernetes clusters, particularly in environments where cost savings, efficiency, and adaptability are key priorities.
Karpenter Demo
Prerequisites
awsCLI tool installedkubectlCLI tool installedhelmCLI tool installed- EKS cluster running (minimum of one small node group with at least one worker node).
Step-By-Step
1 — First, set some environment variables.
export KARPENTER_NAMESPACE="kube-system"
export KARPENTER_VERSION="1.3.3"
export CLUSTER_NAME=<your_cluster_name>
export ALIAS_VERSION="$(aws ssm get-parameter --name "/aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2023/x86_64/standard/recommended/image_id" --query Parameter.Value | xargs aws ec2 describe-images --query 'Images[0].Name' --image-ids | sed -r 's/^.*(v[[:digit:]]+).*$/\1/')"
2 — Then, install the Karpenter on EKS cluster.
helm registry logout public.ecr.aws
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" --create-namespace \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "settings.interruptionQueue=${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait
After that you can verify the Karpenter deployment by kubectl get pods -n kube-system -o wide as shown below.

3 — Configure NodePools to define node requirements. To use Spot instances you can set/add in karpenter.sh/capacity-type requirement to spot, in this demo I just set it to on-demand instance.
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
expireAfter: 72h # 3 * 24h = 72h
limits:
cpu: 100
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "WorkerNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "al2023@${ALIAS_VERSION}"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
You can verify the NodePool by using kubectl describe NodePool default as shown below.
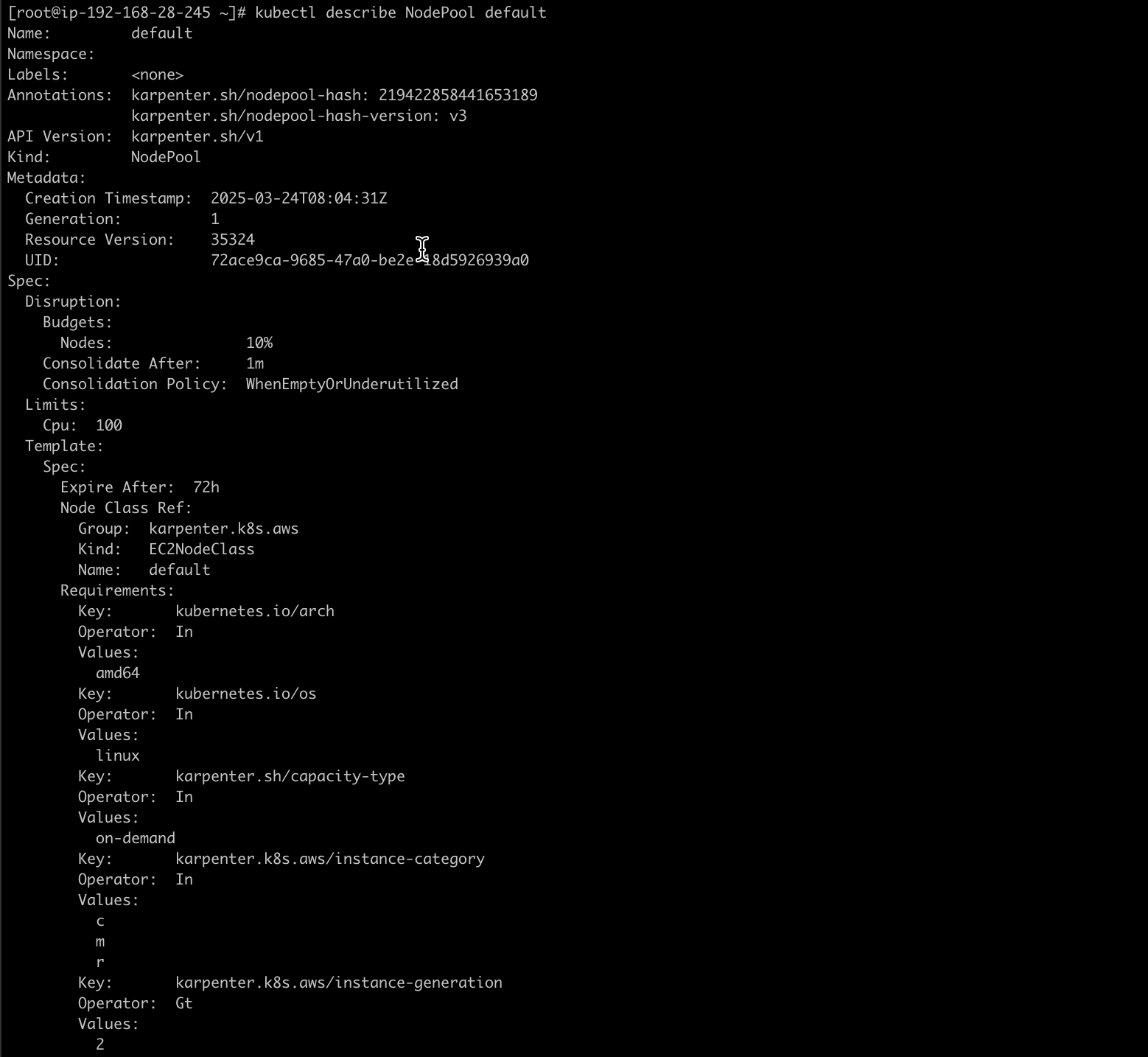
On table below will explain the parameters that I used here.
| Field | Description |
|---|---|
NodePool |
Defines how Karpenter provisions nodes |
requirements |
Sets constraints on OS, instance type, architecture, etc |
nodeClassRef |
Links to an EC2NodeClass |
expireAfter: 72h |
Nodes expire after 72 hours |
limits.cpu: 100 |
Limits total CPU across nodes |
consolidationPolicy: WhenEmptyOrUnderutilized |
Removes underutilized nodes |
role: WorkerNodeRole-${CLUSTER_NAME} |
Defines IAM role for worker nodes |
amiSelectorTerms |
Selects Amazon Linux 2023 AMI |
subnetSelectorTerms |
Selects subnets using tags |
securityGroupSelectorTerms |
Assigns security groups using tags |
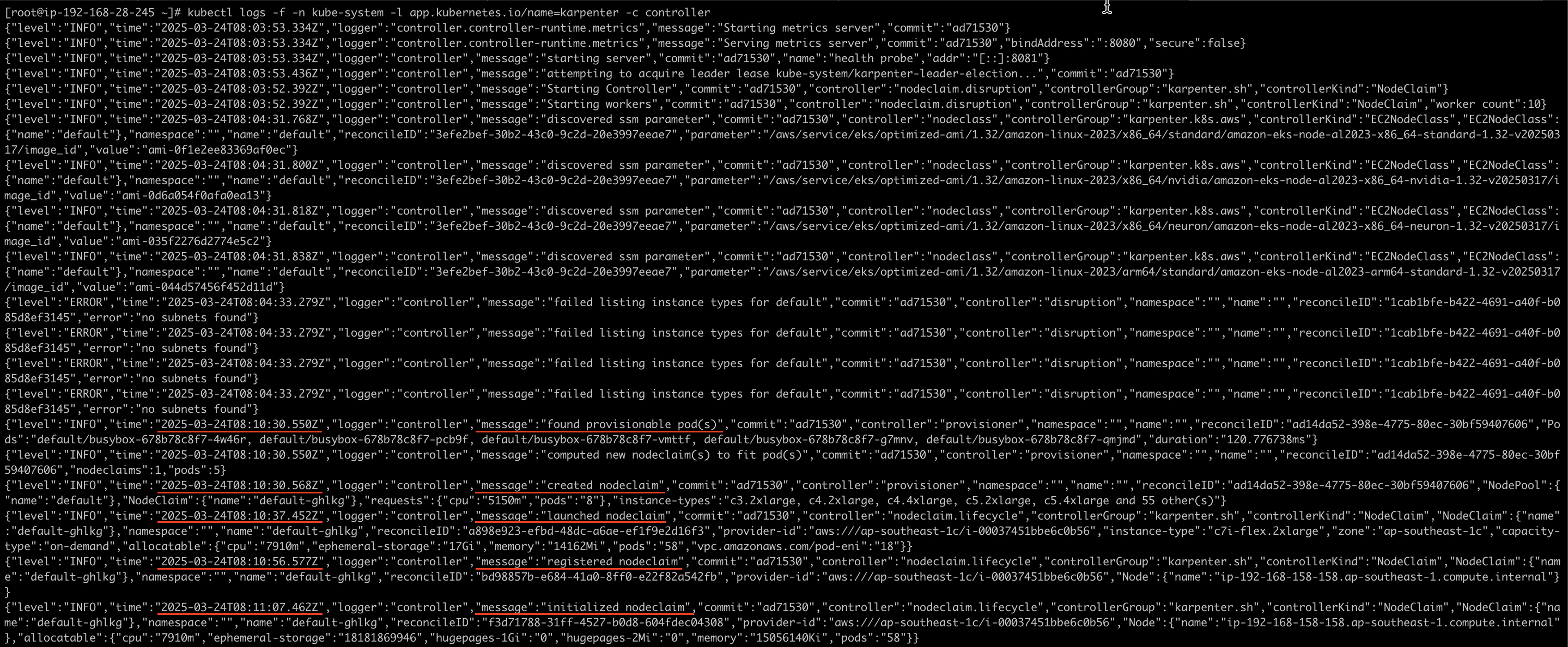
4 — You can watch for Karpenter pod logs first by using this command:
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller
Then, test it by deploying a sample application and scaling it to trigger node provisioning.
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox
spec:
replicas: 0
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: busybox
command: ["sleep", "3600"]
image: busybox:latest
resources:
requests:
cpu: 1
securityContext:
allowPrivilegeEscalation: false
EOF
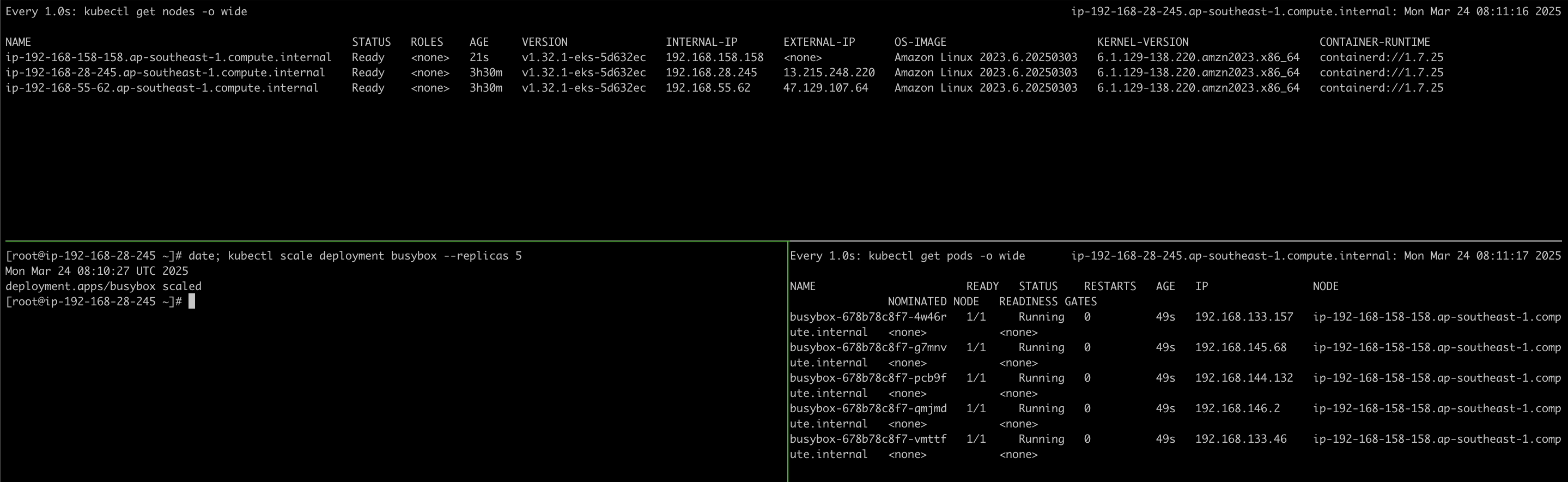
kubectl scale deployment busybox --replicas 5
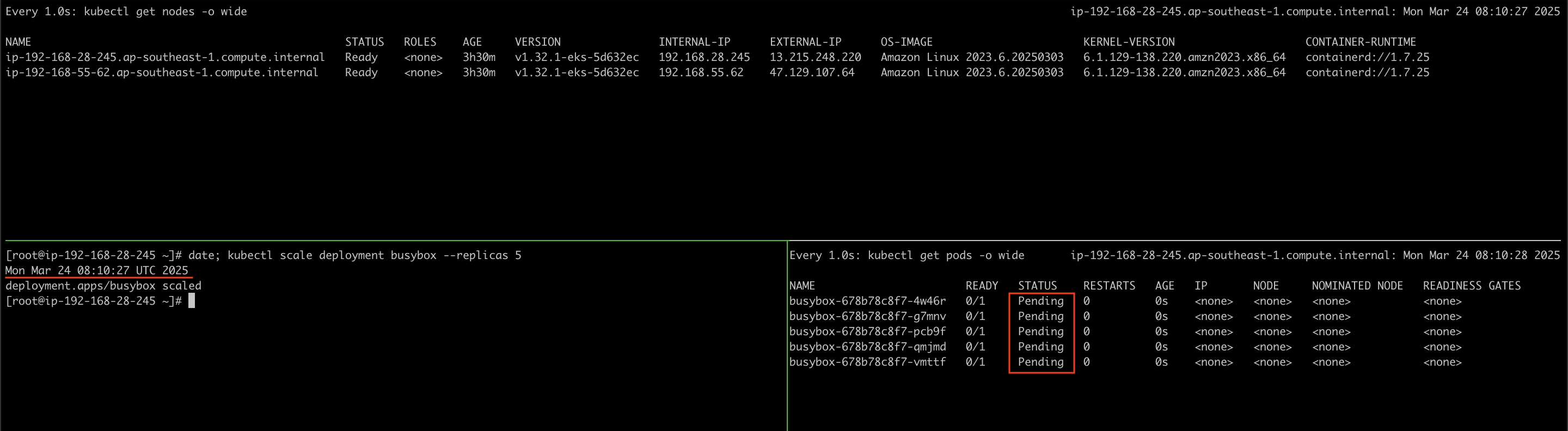
As you can see on the image above I scaled up the deployment at 08:10:27 UTC, while pods pending I also tailing to the Karpenter logs. Looks like the Karpenter knows that there are pods that provisionable or on pending state at 08:10:30 UTC, then create a node until initialized the node at 08:11:07 UTC.
On EC2 Instance in AWS Console looks that a new instance has been appear.
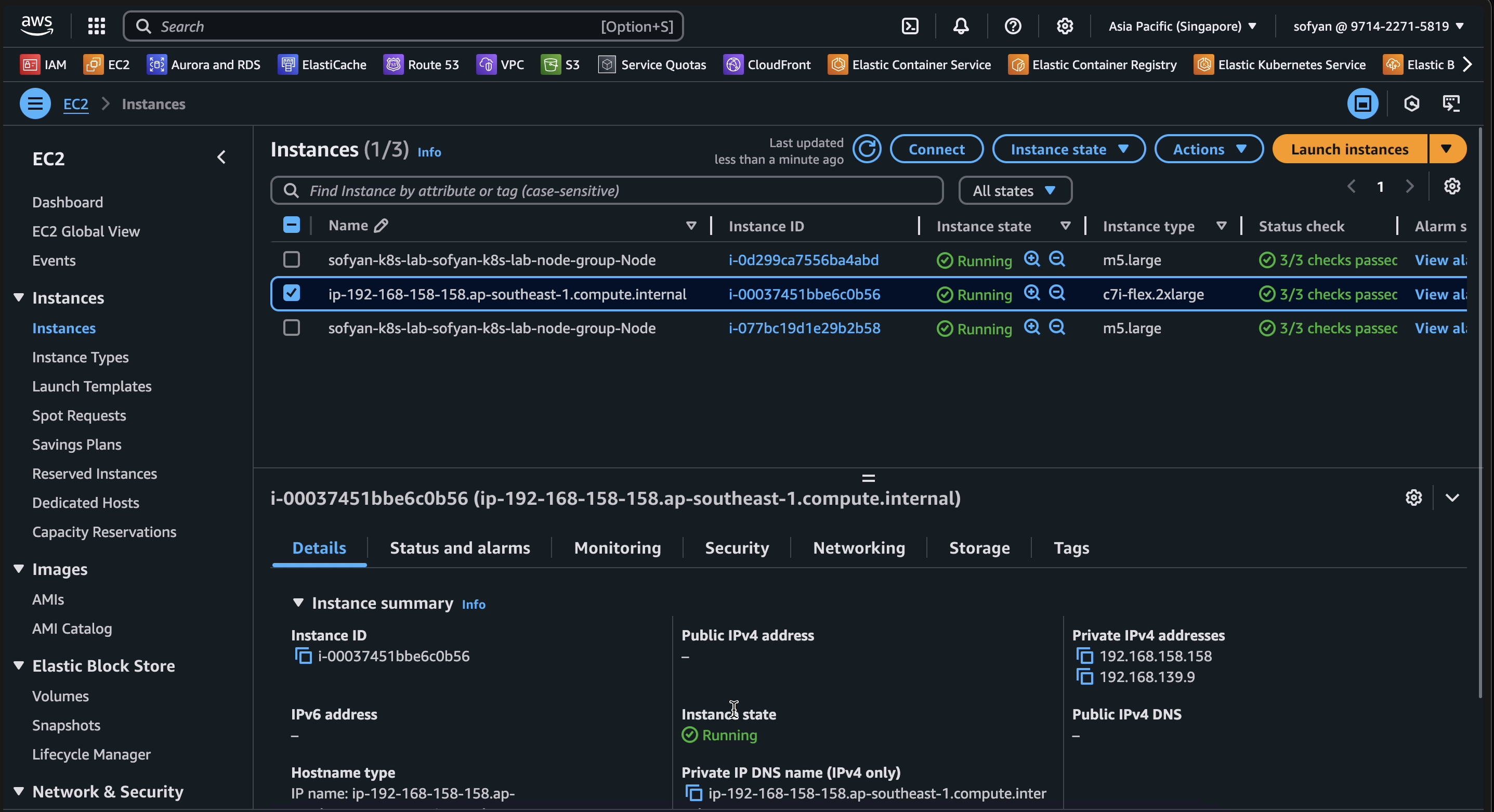
5 — Verify on EKS cluster, that node has been added to cluster and make sure pods pending are scheduled and running on that new node.
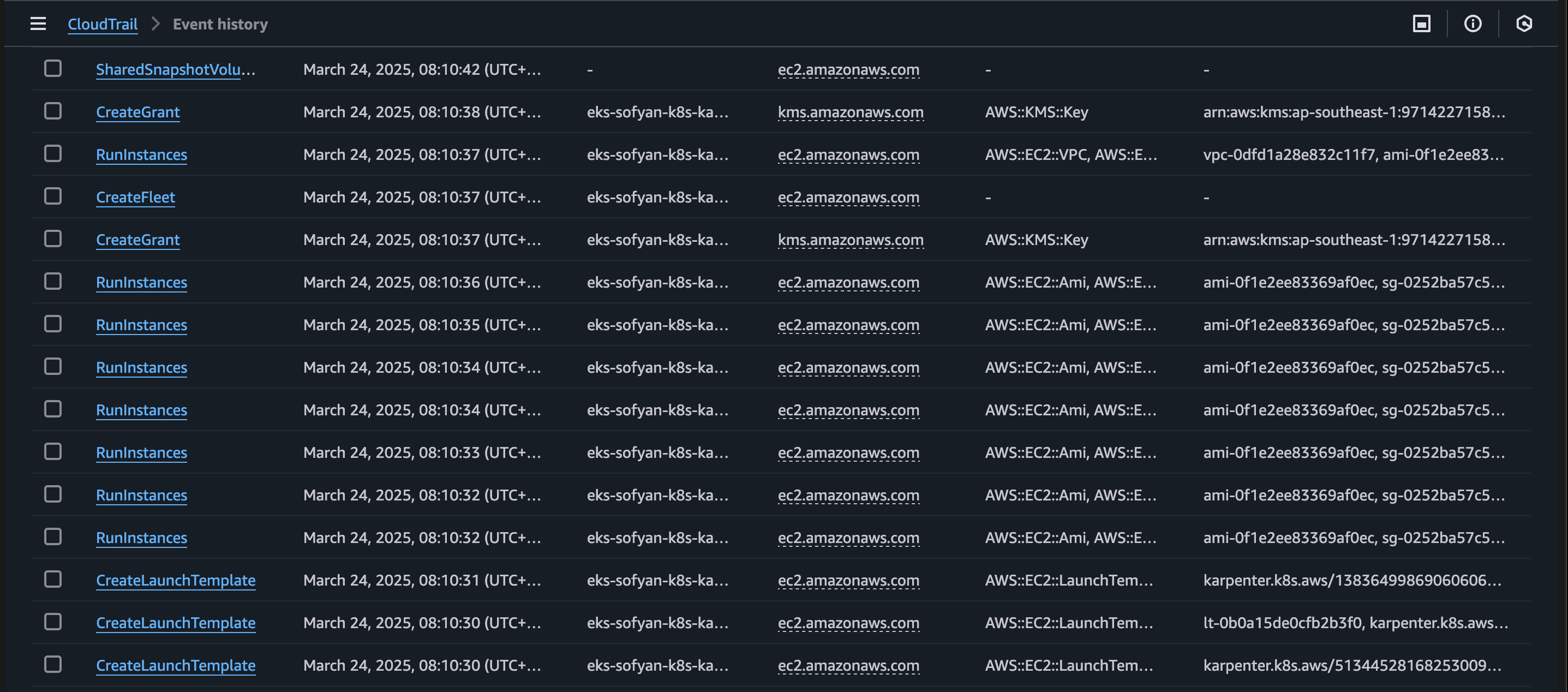
We also could verify on AWS CloudTrail to track what Karpenter do within your AWS account as shown below.
6 — Scale down the deployment and see if node will be removed from cluster.
kubectl delete deployment busybox

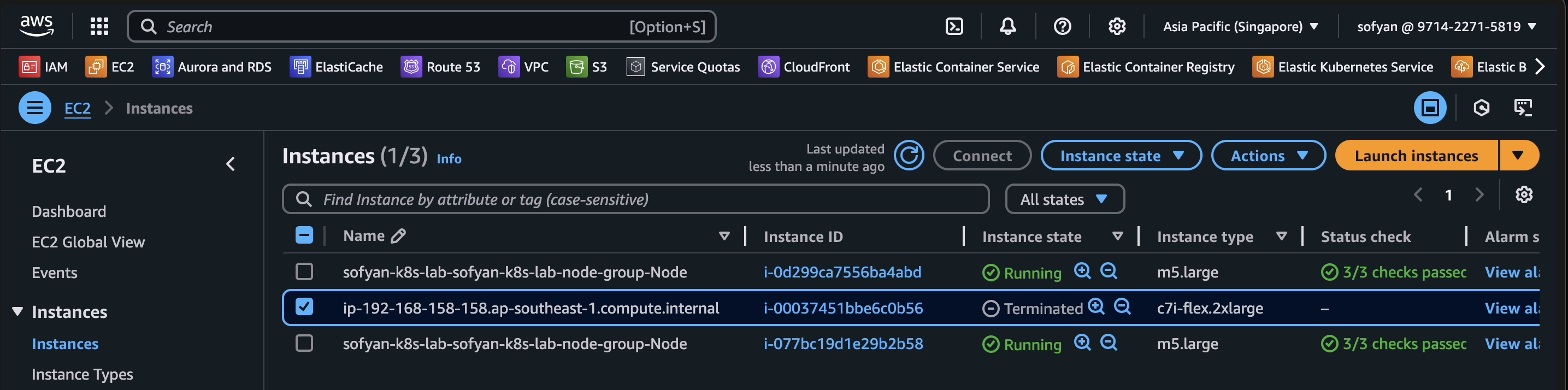
As you can see on screenshot below, the node was removed from cluster.

From the AWS console also, the instance was terminated automatically by Karpenter. This is the reason why Karpenter is more than autoscalers, Karpenter offers more intelligent scheduling, cost efficiency, and workload aware provisioning.
Conclusion
Karpenter is open-source framework and strong support from AWS have made it a popular choice for businesses in the cloud. As companies that focus on scaling and saving money, Karpenter is unique approach makes it a must-have tool, and it’s sure to stay relevant in the cloud world. Karpenter does more than just traditional autoscalers. While its primary role is to automatically adjust the number of nodes in a Kubernetes cluster based on resource demand, it also offers advanced features that make it a more comprehensive and powerful tool.
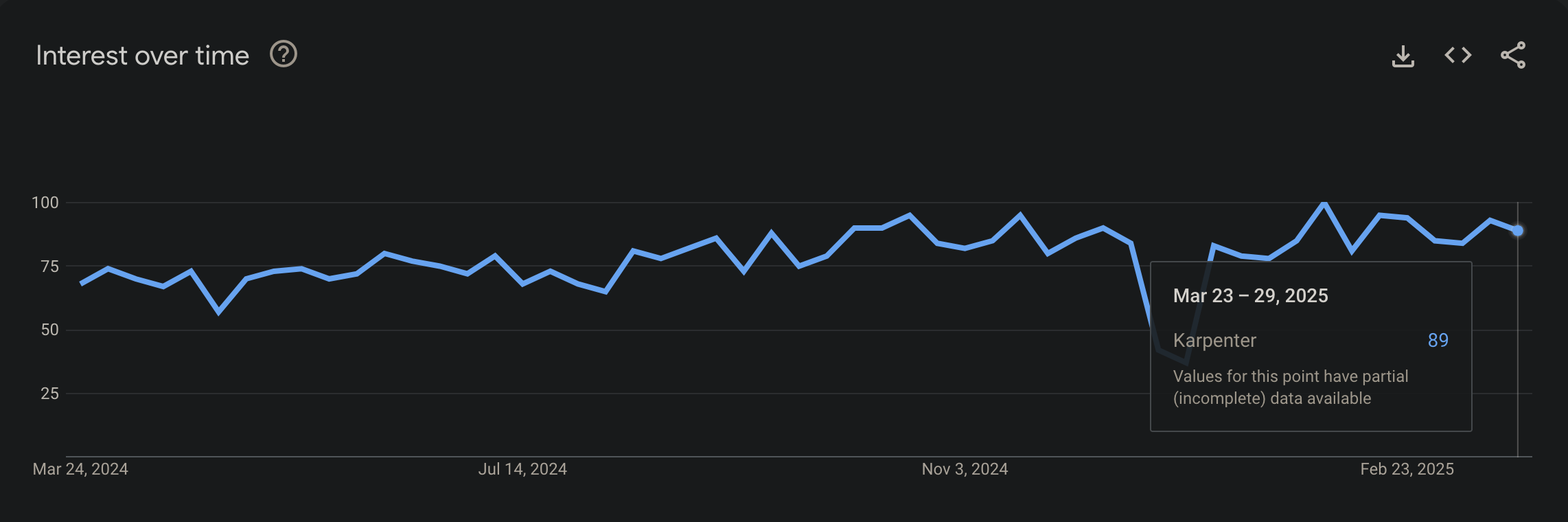
In 2025, Google Trends show that Karpenter is getting a lot of attention. This is because more companies are using Kubernetes to run their apps, and they need better tools to manage their computing resources. Karpenter is better than older tools because it can quickly adjust how much computing power is used and can use cheaper options from the cloud.
References
- Fairwinds: Kubernetes in 2025 Top 5 Trends & Predictions
- AWS Blog: Introducing Karpenter An Open-Source High-Performance Kubernetes Cluster Autoscaler
- Karpenter Getting Started with Karpenter Guide
- Karpenter Concepts Scheduling for NodePools
- Optimizing Kubernetes compute costs with Karpenter consolidation



